What Is a Decision Tree?
A decision tree is a type of supervised machine learning used to categorize or make predictions based on how a previous set of questions were answered. The model is a form of supervised learning, meaning that the model is trained and tested on a set of data that contains the desired categorization.
The decision tree may not always provide a clear-cut answer or decision. Instead, it may present options so the data scientist can make an informed decision on their own. Decision trees imitate human thinking, so it’s generally easy for data scientists to understand and interpret the results.
SPONSORED SCHOOLS
Massachusetts Institute of Technology
MIT Machine Learning
Get recognized for your new-found knowledge of machine learning in business with a digital certificate of completion from MIT Sloan.
- Create a practical action plan to strategically implement machine learning in business
- 6 weeks, excluding 1 week orientation
- 6–8 hours of self-paced learning per week, entirely online
SPONSORED
How Does the Decision Tree Work?
Before we dive into how a decision tree works, let’s define some key terms of a decision tree.
- Root node: The base of the decision tree.
- Splitting: The process of dividing a node into multiple sub-nodes.
- Decision node: When a sub-node is further split into additional sub-nodes.
- Leaf node: When a sub-node does not further split into additional sub-nodes; represents possible outcomes.
- Pruning: The process of removing sub-nodes of a decision tree.
- Branch: A subsection of the decision tree consisting of multiple nodes.
A decision tree resembles, well, a tree. The base of the tree is the root node. From the root node flows a series of decision nodes that depict decisions to be made. From the decision nodes are leaf nodes that represent the consequences of those decisions. Each decision node represents a question or split point, and the leaf nodes that stem from a decision node represent the possible answers. Leaf nodes sprout from decision nodes similar to how a leaf sprouts on a tree branch. This is why we call each subsection of a decision tree a “branch.” Let’s take a look at an example for this. You’re a golfer, and a consistent one at that. On any given day you want to predict where your score will be in two buckets: below par or over par.
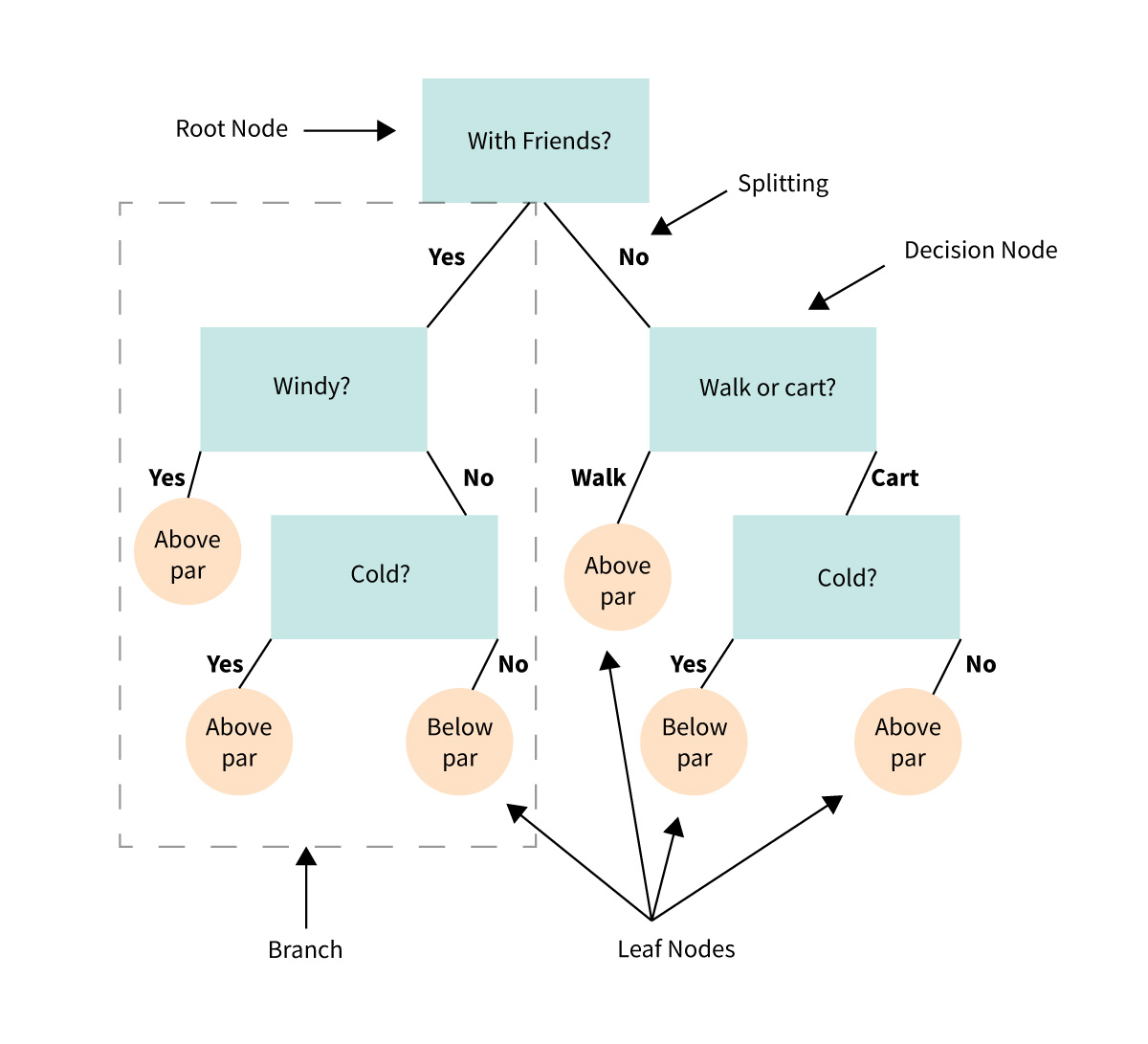
While you are a consistent golfer, your score is dependent on a few sets of input variables. Wind speed, cloud cover and temperature all play a role. In addition, your score tends to deviate depending on whether or not you walk or ride a cart. And it deviates if you are golfing with friends or strangers.
In this example, there are two leaf nodes: below par or over par. Each of the input variables will determine decision nodes. Was it windy? Cold? Did you golf with friends? Did you walk or take a cart? With enough data on your golfing habits (and assuming you are a consistent golfer), a decision tree could help predict how you will do on the course on any given day.
Decision Tree Variables and Design
In the golf example, each outcome is independent in that it does not depend on what happened in the previous coin toss. Dependent variables, on the other hand, are those that are influenced by events before them.
Building a decision tree involves construction, in which you select the attributes and conditions that will produce the tree. Then, the tree is pruned to remove irrelevant branches that could inhibit accuracy. Pruning involves spotting outliers, data points far outside the norm, that could throw off the calculations by giving too much weight to rare occurrences in the data.
Maybe temperature is not important when it comes to your golf score or there was a day when you scored really poorly that’s throwing off your decision tree. As you’re exploring the data for your decision tree, you can prune specific outliers like your one bad day on the course. You can also prune entire decision nodes, like temperature, that may be irrelevant to classifying your data.
Well-designed decision trees present data with few nodes and branches. You can draw a simple decision tree by hand on a piece of paper or a whiteboard. More complex problems, however, require the use of decision tree software.
SPONSORED SCHOOLS
University of Surrey
Master of Science in Artificial Intelligence
The MSc People-Centred Artificial Intelligence course equips you with fundamental AI concepts and universal machine learning tools essential for any AI job role, as well as specific practical and research skills in key AI topics and applications. Our approach places humans at the heart of innovation and implementation, and prepares you to shape the future of ethical, inclusive and responsible AI.
- Complete the course in 24 months, part time.
- No application fees or standardised test scores required.
- Choose from three start dates per year (September, February, June).
Maryville University
Master of Science in Artificial Intelligence
Earn your MS in Artificial Intelligence online from Maryville University in as few as two years. Prepare to develop and use AI and machine learning tools, and practice ethical stewardship of AI tech.
- Take two classes per term and graduate in as few as two years
- Complete practical, project-based coursework that is highly relevant to top trends and concepts in AI
- Learn to use in-demand tools like R, Python, C++, Amazon Web Services and Google Colaboratory
- Build proficiency in crucial areas like ethics of AI, problem solving, machine learning, computer programming, natural language processing, robotics, machine vision and implementing AI in society and business.
SPONSORED
Types of Decision Trees
There are two main types of decision trees: categorical and continuous. The divisions are based on the type of outcome variables used.
Categorical Variable Decision Tree
In a categorical variable decision tree, the answer neatly fits into one category or another. Was the coin toss heads or tails? Is the animal a reptile or mammal? In this type of decision tree, data is placed into a single category based on the decisions at the nodes throughout the tree.
Continuous Variable Decision Tree
A continuous variable decision tree is one where there is not a simple yes or no answer. It’s also known as a regression tree because the decision or outcome variable depends on other decisions farther up the tree or the type of choice involved in the decision.
The benefit of a continuous variable decision tree is that the outcome can be predicted based on multiple variables rather than on a single variable as in a categorical variable decision tree. Continuous variable decision trees are used to create predictions. The system can be used for both linear and non-linear relationships if the correct algorithm is selected.
What Are the Applications for a Decision Tree?
Decision trees are useful for categorizing results where attributes can be sorted against known criteria to determine the final category.
Decision trees map possible outcomes of a series of related choices. Some applications for decision trees include:
Customer Recommendation Engines
Customers buying certain products or categories of products might be inclined to buy something similar to what they’re looking for. That’s where recommendation engines come in. They can be used to push the sale of snow gloves with a purchase of skis or recommending another holiday movie after you’ve just finished watching one.
Recommendation engines can be structured using decision trees, taking the decisions made by consumers over time and creating nodes based off of those decisions.
Identifying Risk Factors for Depression
A study conducted in 2009 in Australia tracked a cohort of over 6,000 people and whether or not they had a major depressive disorder over a four-year period. The researchers took inputs like tobacco use, alcohol use, employment status and more to create a decision tree that could be used to predict the risk of a major depressive disorder.
Medical decisions and diagnoses rely on multiple inputs to understand a patient and what may be the best way to treat them. A decision tree application like this can be a valuable tool to health care providers when assessing patients.
Advantages and Disadvantages of a Decision Tree
A decision tree visually represents cause and effect relationships, providing a simple view of complex processes. They can easily map nonlinear relationships. They are adaptable to solve both classification and regression problems. With a decision tree, you can clarify risks, objectives and benefits.
Because of the tree structure’s simple flowchart structure, it’s one of the fastest methods to identify significant variables and relationships between two or more variables. If a data scientist is working on a problem with hundreds of variables, the decision tree will help identify the most significant ones. They’re also considered easy to understand even for people without an analytical background. The visual output means statistical knowledge is not necessary. It’s usually easy to see the relationships between the variables.
Sometimes, however, decision trees have limitations. Understanding the advantages and disadvantages of decision trees can help make the case for using one.
Advantages
- Works for numerical or categorical data and variables.
- Models problems with multiple outputs.
- Tests the reliability of the tree.
- Requires less data cleaning than other data modeling techniques.
- Easy to explain to those without an analytical background.
Disadvantages
- Affected by noise in the data.
- Not ideal for large datasets.
- Can disproportionately value, or weigh, attributes.
- The decisions at nodes are limited to binary outcomes, reducing the complexity that the tree can handle.
- Trees can become very complex when dealing with uncertainty and numerous linked outcomes.
Learn More About Data Science
SPONSORED SCHOOLS
SPONSORED
Decision tree algorithms are powerful tools for classifying data and weighing costs, risks and potential benefits of ideas. With a decision tree, you can take a systematic, fact-based approach to bias-free decision making. The outputs present alternatives in an easily interpretable format, making them useful in an array of environments. As a data scientist, the decision tree will be a key part of your tool kit.
To launch your data science career, choose the best data science master’s program for you.
Sources
https://towardsdatascience.com/decision-trees-in-machine-learning-641b9c4e8052
https://medium.com/swlh/a-beginners-guide-to-decision-trees-84ca34927818
https://www.lucidchart.com/pages/decision-tree
https://towardsdatascience.com/decision-tree-in-machine-learning-e380942a4c96
https://hackernoon.com/what-is-a-decision-tree-in-machine-learning-15ce51dc445d
https://www.xoriant.com/blog/product-engineering/decision-trees-machine-learning-algorithm.html
https://www.youtube.com/watch?v=FCJ3o0Ze–M